From www.astrology-and-science.com 20m 6g 72kb Home Fast-Find Index
Meta-analyses of nearly 300 empirical studies
Putting astrology and astrologers to the test
Geoffrey Dean
Abstract -- Brings together in graphical form meta-analyses of sun sign self-attribution, matching tests, picking own chart, astrologer agreement, Gauquelin's tests of signs, aspects and planets, and lunar and other effects. Altogether there are a total of nine meta-analyses relevant to astrology, including for convenience the ones mentioned elsewhere on this website. Readers wishing to skip details can simply look at the pictures. Differences in statistical variables such as sample size and measurement reliability are like magic. They produce apparent effects and apparent effect sizes out of nothing, all of them spurious. Meta-analysis allows a set of effect sizes to be corrected for these spurious effects (something not possible with an individual study) to see if there is a real effect. Since the 1970s its ability to deal with spurious effects has revolutionised research wherever effect sizes are reported, and today many thousands of meta-analyses have been made. When applied to nearly 300 empirical astrological studies, many of them by astrologers, meta-analysis reveals zero support for effect sizes of around r = 0.7 that are representative of astrological claims. Mean effect size and number of studies are: sun sign self-attribution 0.070 (26) and controls -0.020 (9), matching birth charts to owners 0.034 (54), picking own chart 0.020 (11), agreement between astrologers 0.098 (26), Gauquelin's tests of signs and aspects 0.007 (62) and planets 0.044 (35), lunar effects 0.012 (50), and radio propagation effects 0.010 (10). If you are looking for something where nothing is true and everything is permitted, then astrology seems to be an excellent choice.
Effect sizes, meta-analysis, and plots of results are cited in various articles on this website, most notably in Case For and Against Astrology (looks at accuracy, agreement), Artifacts in data (accuracy, sample size), Effect Size (accuracy), and Phillipson's interview of researchers (accuracy, agreement, sample size), see Index. The present article brings together in graphical form a total of nine meta-analyses relevant to astrology, including for convenience the ones mentioned above (so be prepared for some repetition), at a fairly technical level. It starts with a look at meta-analysis and how to do it. Readers wishing to skip details can simply look at the pictures.
When studies disagree
Take personnel psychology for example. By the 1960s personnel psychology
had thousands of studies on the validity of aptitude tests, and Figure 1
(left) shows just a few of them. Each plot shows the observed effect
size (as a correlation) vs number of studies (as % of the total), and
disagreement is the rule. Some studies report a strong positive effect,
others report a weak or even negative effect. Because of this
disagreement it was held that no conclusion about the validity of a
particular test was possible. It all seemed to depend on the particular
person, job, and situation.
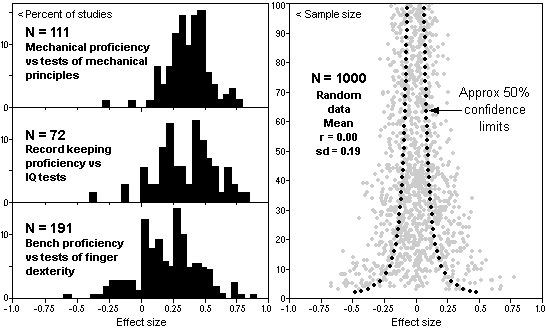
Figure 1. Effect sizes in personnel psychology. Left Effect size vs number of studies for three aptitude tests. Sample size in each study is typically around 60. In each plot there is wide disagreement. Some studies report a strong positive effect, others report a weak or even negative effect. From Ghiselli ES, The Validity of Occupational Aptitude Tests, Wiley, New York, 1966:29. Right: 50% confidence limits for r = 0.00 superimposed on 1000 sets of data drawn at random from a population whose true effect size r = 0.00. The confidence limits are approximated by 0.6745/sqr(N) where 0.6745 is half the area under a normal curve and N is the sample size. Due to sampling fluctuations each sample rarely matches the population, just as a hand in cards rarely contains equal numbers of each suite, which means that the observed effect size can be quite different from the true effect size. In this case the observed effect size can exceed ±0.5 even though the true effect size is zero, especially with small sample sizes, all due to the natural fluctuations inherent in sampling. By plotting effect sizes together with confidence limits, we can see at a glance what is happening.
Then in the 1970s came a revolution in thinking. It was realised that much of the variation between studies was due to differences in statistical variables such as sample size and measurement reliability. For example in Figure 1 (right) the true effect size is zero, yet the observed effect size can exceed ±0.5, all due to the natural fluctuations inherent in sampling -- and this is without considering other statistical variables such as measurement reliability. In general terms the fluctuations vary as 1/sqr(N), where N is the sample size. (N also denotes the number of studies, in which case the distinction will be evident from the context.)
Conversely, the sample size needed to reliably detect effect size r is roughly 10/r2. In technical terms to reliably detect r means detecting r in 4 out of 5 tests at a two-sided significance level of p = 0.05. So if we want to reliably detect an effect size of say 0.10, we will need a sample size of around 10/0.102 = 1000, or very considerably more than the 10 typically used by astrologers in the past. Also, if we use small samples then our observed effect size will seldom be a good indication of the true effect size. Indeed, sampling variations are like magic. They produce something out of nothing that is interesting, exciting, full of promise, and totally spurious. So what is the answer?
Meta-analysis
The answer is meta-analysis. Meta-analysis allows a set of effect sizes
to be corrected for these spurious effects (something not possible with
an individual study) to see if there is a real effect. It begins by
establishing an effect size as a correlation r and sample size N for
each study. (Alternatively it can use effect size d, the difference in
standard deviations between observation and expectancy, but this variant
is not used here.) In the bare bones procedure of JE Hunter & FL
Schmidt, Methods of Meta-Aanalysis: Correcting Error and Bias in
Research Findings, Sage, Newbury Park CA, 1990:43ff, it then calculates
the following:
Weighted mean r = sum of (N x r for that N) / total N
Total variance = sum of (N x (r - mean r)2) / total N
Sampling error variance = (1 - (mean r)2)2 / (mean N - 1)
The above calculations are straightforward and require only simple arithmetic. As a rule of thumb, if the sampling error variance is more than 75% of the total variance, we conclude that real differences between studies do not exist. That is, we conclude that the apparent differences are due to sampling fluctuations (ie chance) and other artifacts, not to real differences between studies. If real differences do emerge, we examine the data to see what the cause might be, thus tracking down the variables that matter. Either way, weighted mean r is the best estimate of the effect size, which must then be evaluated for significance in the usual way via its standard deviation = sqr(total variance).
Ideally the effect size we want from each study is the correlation between predictor and reality, not reality as measured by imperfect criteria. But imperfect criteria (test scores, ratings, whatever) are all we have. In principle we can correct for these imperfections, in which case the effect size is described as "corrected for artifacts" or "corrected for attenuation", and the subsequent calculations differ from those shown above. But in practice the necessary data are seldom available, although estimates from other studies are often possible.
Meta-analysis was introduced in the late 1970s and became an instant hit. Its ability to deal with sampling variations and imperfect criteria has revolutionised research in many areas including parapsychology, allowing clear conclusions where previously there was only confusion. Today the number of meta-analyses available in PsycINFO alone exceeds 3000.
Procedure
To meta-analyse empirical studies in astrology we must first retrieve
all existing studies, published or unpublished, and establish an effect
size r and sample size N for each study. Retrieval of studies in
astrology is especially difficult because they tend to be published in
journals not abstracted by computerised databases such as PsycINFO,
which means doing it the hard way, ie by inspecting the relevant
literature, which in turn may be available only in specialised astrology
collections. The studies meta-analysed here represent more than thirty
years of searching and following up leads. In most meta-analyses it is
usual to reject low-quality studies, for example studies poorly
described or lacking proper controls, but in this case, to avoid charges
of bias from astrologers, no studies have been rejected.
Second, we must plot the effect sizes against sample size and 50% confidence limits so we can see everything in one hit. Finally we do a meta-analysis to see what it all means.
Effect sizes and hit rates
Examples of effect sizes are tabulated elsewhere on this website, see
Index. In case you have forgotten, an effect size or correlation ranges
from -1 to +1, with zero indicating no correlation. Between 0 and 1 are
the huge variety of effect sizes actually observed, of which perhaps the
most crucial is 0.4, generally recognised as the lower limit of
usefulness for procedures that are applied to individuals (as astrology
is). That is, unless its effect size routinely exceeds 0.4, astrology
cannot be seen as a useful source of information. If we assume the
expectancy of a hit is 50%, as for tossing coins, then an effect size r
translates to a hit rate of 50+50r%. Thus 0.4 translates to 70%, so you
can see why anything less than 0.4, although non-zero, is also
non-useful.
Effect sizes claimed by astrologers
We can also convert the other way. For example, when Linda Goodman
claims that "An individual's Sun sign will be approximately eighty
percent accurate, sometimes up to ninety percent" (Sun Signs, Harrap,
London, 1968:xvi), this translates to an effect size of about 0.7. My
own surveys of astrologers in the UK (N=40) and Australia (N=16) found
that on average they estimated that 22% of people fit their birth chart
in every possible respect (so r = 1.00), 57% fit their birth chart in
most things (r = 0.7 say), 18% fit their birth chart in a few things
only (r = 0.3 say), and 3% fit their birth chart in almost nothing (r =
0.1 say), which pro rata gives the average fit between birth charts and
their owners as equivalent to r = 0.68, for details see Correlation
1986, 6(2), 7-52. The male astrologers were slightly more conservative
than the female astrologers, but there was no appreciable variation with
experience, which ranged from 1 to 30 years, mean 7 years. There was
good agreement between the two groups (r = 0.93) and fair agreement
between individual astrologers (mean r = 0.47). So we can take 0.7 as a
reasonable ball-park estimate of the effect size that astrologers claim
they are getting in everyday practice.
Note that a tiny effect is not the same as a tiny effect size. The bending of light by gravity is a tiny effect, where the sun deflects the grazing light of a star by 0.000486 degrees, roughly the angle subtended by a human hair at ten metres, but the effect size is 1. That is, if we know the gravity we can exactly predict the bending. So a tiny effect is not the same as a tiny effect size.
Meta-analysis of sun signs
In the 1970s it was found that extraversion scores tended to vary in
accordance with sun sign claims, where odd-numbered signs (Aries
onwards) are said to be extraverted and even-numbered signs (Taurus
onwards) are said to be introverted. The effect replicated and was
hailed by astrologers as scientific proof of their claims. But the
effect size was tiny. The effect also disappeared when people unfamiliar
with sun signs were tested, see Figure 2 below. So it had a simple
explanation -- self-attribution due to prior knowledge of astrology. Ask
Sagittarians (said to be sociable and outgoing) questions related to
extraversion, such as whether they like going to parties, and astrology
might tip their answer in favour of yes rather than no. The effect is an
artifact. It looks like astrology but has a non-astrological
explanation. Nevertheless the power of astrology to shift people's
self-image, however slightly, deserves recognition. The effect size of signs
is further examined later under Gauquelin.
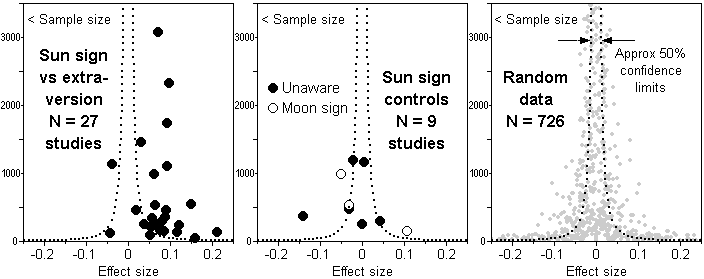
Figure 2. Effect size as a correlation or similar measure for sun sign vs extraversion test scores (usually by EPI or EPQ). Left: The 27 studies to date show a clear positive deviation from r = 0.00. Meta-analysis by the bare bones procedure of Hunter & Schmidt gives a mean r weighted by sample size of 0.070, sd 0.042, p 0.10. (Values of 0.09 cited elsewhere on this website are from earlier meta-analyses based on fewer studies.) Centre: No deviation is observed when subjects are unaware of their Sun sign or when their Moon sign is tested (few people know their Moon sign). Mean r -0.020, sd 0.044, p 0.60. In both cases the sampling variance is 85% or more of the total variance, so there is no real difference between the studies in each plot. Right: 50% confidence limits superimposed on 726 sets of data drawn at random from a population whose true correlation r = 0.00. As in Figure 1, if the true r is zero, as it will be for random data, then on average 50% of the observed values will lie within the 50% confidence limits.
Meta-analysis of tests of birth charts
Take sets of birth charts jumbled up with descriptions of their owners.
Can astrologers match birth charts to owners? In astrology books they do
it all the time with unfailing success. But in the 54 studies to date,
which involved a total of 742 astrologers and 1407 birth charts, the
average success rate was no better than chance, see Figure 4 (left). For
these astrologers, many of them among the world's best, astrology
performed no better than tossing a coin. In a further 18 studies
involving over 650 clients and 2100 readings, clients were unable to
pick their own reading out of several, at least not when cues such as
sun sign names or descriptions were absent, see Figure 3 (centre).
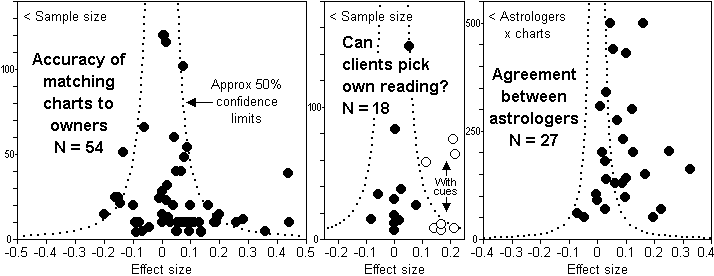
Figure 3. Testing astrologers for their accuracy and agreement. Left: Effect size r for astrologers matching birth charts to personality, occupation, case histories, or their own questionnaires. The plot shows all known studies including unpublished ones and poor quality ones. Mean r 0.035, sd 0.117, p 0.77, equivalent to 51.75% hits when 50% is expected by chance. Median sample size is 13. Observed effect sizes showed no relation to confidence or use of intuition. If astrology delivered as claimed by astrologers, r would be around 0.7. Minimum r for tests generally accepted as being useful is around 0.4. Thus r for IQ vs achievement is around 0.6. Centre: When cues such as sun sign names or descriptions are absent from astrology readings, clients are unable to pick their own when given several. Mean r 0.020, sd 0.040, p 0.61, N 11. When cues are present the effect sizes show a positive deviation. Mean r 0.201, sd 0.125, p 0.11, N 7. In both plots (left and centre) the sampling variance is more than the total variance, so there is no real difference between the studies in each plot. Right: The agreement between astrologers shows a positive deviation. Mean r 0.098, sd 0.065, p 0.13. But none of the observed agreements come anywhere near the agreement of 0.8 generally recognised as being necessary for tests applied to individuals (as astrology is). The sampling variance is about half the total variance, suggesting that real differences exist between studies, no doubt because some chart indications (eg for extraversion) are easier for astrologers to agree on than others (eg for suicide).
Tests of agreement
How well do astrologers agree on what a given birth chart indicates? To
date 28 studies have put this to the test using in total more than 550
astrologers and 750 birth charts. Typically each test looked at how well
5 to 30 astrologers agreed on what a given chart indicated about its
owner. Their average agreement was dismal, better than tossing a coin
but nowhere near the minimum agreement acceptable for tests applied to
individuals, see Figure 3 (right). Again, many of these astrologers were
among the world's best.
Sampling fluctuations revisited
A further demonstration of the power of sampling fluctuation to produce
something out of nothing is shown in Figure 4, repeated from Figures 3
and 4 in Phillipson interview of researchers. When exploring a new
chart factor (in astrology there are always new chart factors) an
astrologer will normally look at a range of charts, and may potentially
end up with a range of effect sizes like those shown. If they are
careful to report only the larger effect sizes, they can create support
for the new factor where none actually exists. Since their sample sizes
are likely to be low, the range of effect sizes is likely to be high,
making it easy to make amazing (but totally spurious) discoveries.

Figure 4. How a small sample size scatters the effect size. Left: The 54 studies of Figure 3 arranged in order of effect size. Meta-analysis has shown that their scatter is entirely explained by sampling fluctuations. Similarly, if the two studies using 120 birth charts (black dots) are divided into 24 studies of 10 charts each, the same marked scatter emerges even though the original effect size was close to zero. Further subdivision increases the scatter. Right: The same results grouped by sample size. As the sample size increases from left to right, the effect sizes show a general decrease in scatter as shown by the trend in bar lengths. The length of each bar is ±2 standard deviations, which is the range within which 95% of the results from a large number of repeat studies are expected to fall. In each case the effect size of r = 0 (the null hypothesis) falls well within each range, confirming that these astrologers were generally unable to match charts to their owners better than tossing a coin.
Meta-analysis of the Gauquelin findings
Michel Gauquelin (1928-1991) began by testing traditional claims ranging
from simple ones such as zodiac signs vs personality to more complex
ones such as transits at death and planetary aspects between family
members. His findings were uniformly negative. In 1955 he published his
results, stressing that they represent "a considerable inquiry in the
testing of astrological rules with large and varied samples. It is
necessary to stress that the results demolish astrology more than they
might appear ... because they attack not the claims of particular
authors but the elementary basis of the doctrine itself" (L'Influence des
Astres, 1955:62).
The situation changed when Gauquelin looked at eminent professional people such as doctors and scientists. He found that they tended to be born with a surplus or deficit of certain planets in the areas just past rise or culmination, but only if the people were eminent and born naturally, and that ordinary people with such features tended to pass them on to their children. Both tendencies were too weak to be of practical use and often required thousands of births for their reliable detection. Figure 5 illustrates the marked difference in effect size between Gauquelin's negative and positive results.

Figure 5. Effect size vs sample size for the Gauquelin findings. Left: Gauquelin's 51 tests of signs (Sun, Moon, MC, and Ascending) and 11 tests of aspects vs the occupation or personality of eminent professionals as predicted by astrology. Mean r 0.007, sd 0.006, p 0.29. Note that negative effect sizes (like Earthy farmers avoiding Water signs) cannot be counted as misses as in Figure 2, so what matters is the distribution of results with respect to the 50% confidence limits. Most results are within these limits because they are an average across relevant signs, which has reduced their scatter. Right: Effect sizes for planetary effects in Gauquelin's early studies of ten professional groups (often involving the same samples as on left), his 17 later studies, and eight independent studies including those by skeptics. The last two tend to involve smaller sample sizes reflecting the difficulty of finding new data. Mean r 0.044, sd 0.019, p 0.02, equivalent to 52.2% hits when 50% is expected by chance. This time most of the results are beyond the 50% confidence limits, indicating that they are unlikely to have arisen by chance. Not shown are effect sizes for parent-children effects, typically about 0.02 (as phi) for N = 16,000.
As shown elsewhere on this website under Gauquelin, the late Michel Gauquelin's negative results are ignored by astrologers, and his positive results are consistent with the presence of social artifacts. But even if positive effects persist when social artifacts are controlled, their effect sizes remain far too small to be commensurate with the r = 0.7 that astrologers claim to achieve. In any case, astrologers do not claim that astrology fails to work for half the planets, for signs, for aspects, for character, or (on Gauquelin's figures) for the 99.994 percent of the population who are not eminent.
Meta-analysis of miscellaneous effects
Many people believe that human behaviour is influenced by the Moon. In
his book on lunar effects, Arnold Lieber claims his research shows a
"lunar influence on violent behaviour, with implications for psychiatry,
medicine, and the behavioural sciences" (The Lunar Effecxt, Doubleday,
New York 1978:xii). But a later meta-analysis by Rotton & Kelly
(Psychological Bulletin 1985, 97, 286-306) of 37 lunar-lunacy studies
involving homicide, crime, murder, psychiatric admissions, crisis calls
or suicide found no significant effects and no replicability. "For every
study that has recorded more lunacy when the moon is full, another has
recorded less" (p.301). A plot of effect sizes that includes more recent
studies is shown in Figure 6 (left), again with no significant effects.
Miscellaneous astrological studies are shown in Figure 6 (right), but
despite the diversity of topic none show significant results.

Figure 6. Lunar and other studies. Left The mean effect size for 50 lunar studies, some of which have impressively large sample sizes, is 0.012 sd 0.066 p 0.85. The sampling variance is much less than the total variance so there are real differences between studies. Right From the top are John Nelson's forecasts of radio quality, whose mean effect size for 5507 forecasts is 0.010, sd 0.036, p 0.61, N 10, see Correlation 1983, 3(1),4-37. On the right, the initially promising results for red hair and Mars rising failed to replicate as the sample size increased. On the left, Terry Dwyer's study of Pluto meanings using 175 subjects gave an effect size in the wrong direction, see Correlation 1987, 7(2), 9-21. Centre, Peter Robert's study of 128 people born on six dates found no clear parallels in personality scores, appearance, handwriting, names, interests, occupation, or life events. The strong similarities predicted by astrology were simply not there. See Roberts & Greengrass, The Astrology of Time Twins, Pentland Press 1994.
The nearly 300 empirical studies meta-analysed in this article are perhaps half of all empirical studies in astrology. The other half is generally only marginally relevant (eg studies of the acceptance of Barnum statements or of seasonal effects on suicide), or is difficult to reduce to an effect size (eg lists of the top aspects in cases of X), or is without controls (eg testing a chart indication on the same group used to derive the indication).
Discussion
To critics, astrology's failure to deliver is unremarkable because its
alleged efficacy is explained by the same hidden persuaders (perceptual
and cognitive biases) that underlie proven invalid approaches such as
phrenology and bloodletting. Today more than thirty hidden persuaders
are known, see the Index on this website. Each hidden persuader creates
the illusion that astrology works, all are used routinely in consulting
rooms, all lead to client satisfaction -- and none require that
astrology be true. But if clients are going to be satisfied, astrologers
can hardly fail to believe in astrology. In this way a vicious circle of
reinforcement is established whereby astrologers and clients become more
and more persuaded that astrology works.
Astrologers predictably reject such views. They say test results are negative because the tests were too difficult or were made by people hostile to astrology (no matter that many were made by astrologers) or were not representative of what happens in their consulting rooms. They say you cannot test astrology by science, which if true would seem to deny their appeals to experience. Or they see bad news as proof of astrology's subtlety, so it is right even when it is wrong. Nevertheless meta-analysis shows that astrologers, even those who are among the world's best, cannot usefully agree on what a birth chart indicates. So how can they know that astrology works? Indeed, why should anyone bother with astrology in the first place?
Originally astrologers claimed factual links between the heavens and human affairs, and such views continued through the 1950s. Then the rising interest in the inner person, and the rising frequency of disconfirming empirical studies, led to a retreat from factual claims to ones involving meaning. To most astrologers "astrology works" now means "astrology is meaningful." And astrology does indeed excel at being meaningful because it involves seeing faces in clouds of planetary gods. Because the ancient Greek founders of astrology chose gods that mirrored human conditions, the faces we see are our own, for example Mars warlike, Jupiter benevolent, Saturn wise. Astrology then guarantees a match with this celestial identikit by being unrelentingly flexible.
Thus hard aspects can be simultaneously bad because their obstacles lead to failure and good because their challenges lead to success. If an awkward indication cannot be overturned by another factor, standard practice allows it to be explained away as untypical, or as unfulfilled potential, or as repressed, or as an error in the birth time, or as an outcome of the practitioner's fallibility. So it is always possible to fit any birth chart to any person, making it a most efficient focus for therapy by conversation. Once the astrologer and client are talking, the birth chart can mostly be ignored except as a convenient means of changing the subject.
Clearly this kind of astrology does not need to be true, and attacking it on the basis of meta-analytic outcomes would be irrelevant. However, meta-analysis becomes immediately relevant should an astrologer claim that astrology needs to be true, because it denies beyond doubt any useful factual links between birth chart and person. If you are looking for something where nothing is true and everything is permitted, then astrology seems to be an excellent choice.
References
An updated meta-analysis, with full details of the studies
meta-analysed, is in the book Astrology under Scrutiny, see bottom of home
page.
From www.astrology-and-science.com 20m 6g 72kb Home Fast-Find Index